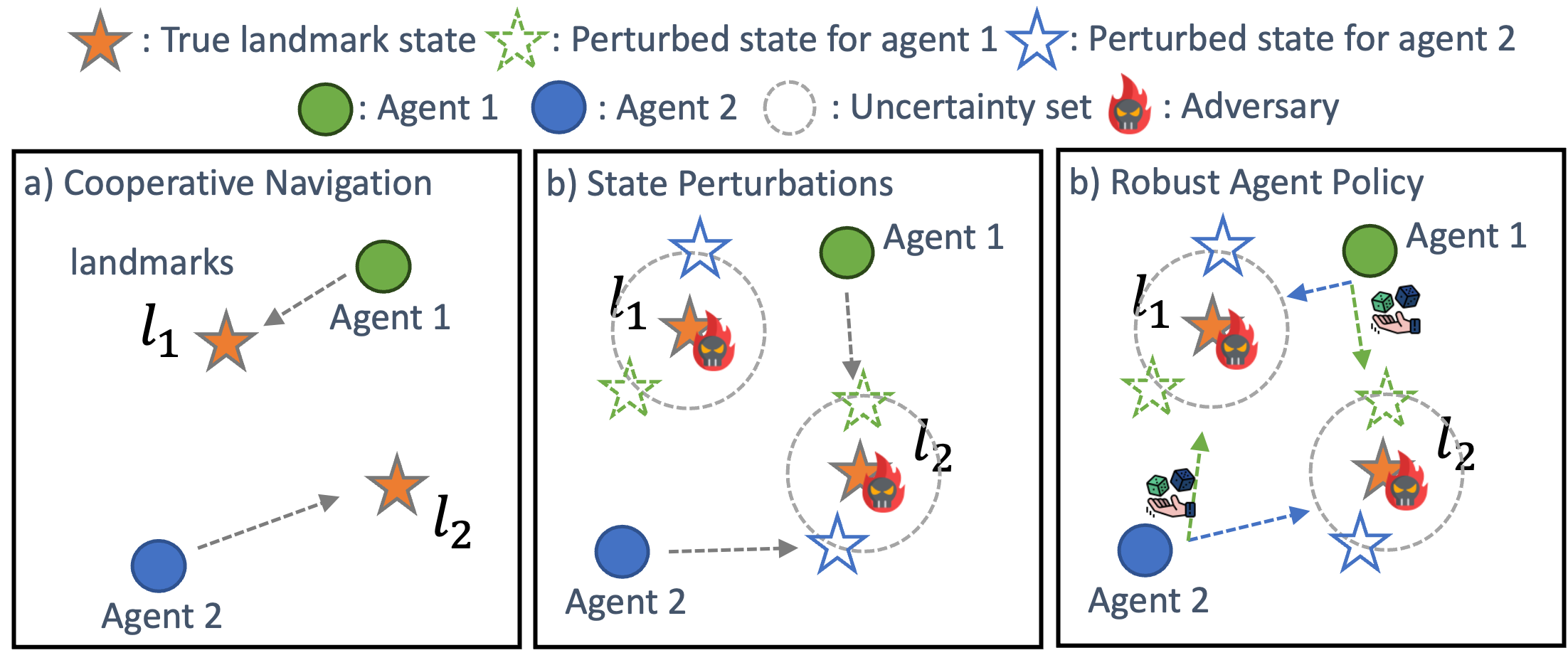
Various methods for Multi-Agent Reinforcement Learning (MARL) have been developed with the assumption that agents' policies are based on accurate state information. However, policies learned through Deep Reinforcement Learning (DRL) are susceptible to adversarial state perturbation attacks. In this work, we propose a State-Adversarial Markov Game (SAMG) and make the first attempt to investigate different solution concepts of MARL under state uncertainties. Our analysis shows that the commonly used solution concepts of optimal agent policy and robust Nash equilibrium do not always exist in SAMGs. To circumvent this difficulty, we consider a new solution concept called robust agent policy, where agents aim to maximize the worst-case expected state value. We prove the existence of robust agent policy for finite state and finite action SAMGs. Additionally, we propose a Robust Multi-Agent Adversarial Actor-Critic (RMA3C) algorithm to learn robust policies for MARL agents under state uncertainties. Our experiments demonstrate that our algorithm outperforms existing methods when faced with state perturbations and greatly improves the robustness of MARL policies.
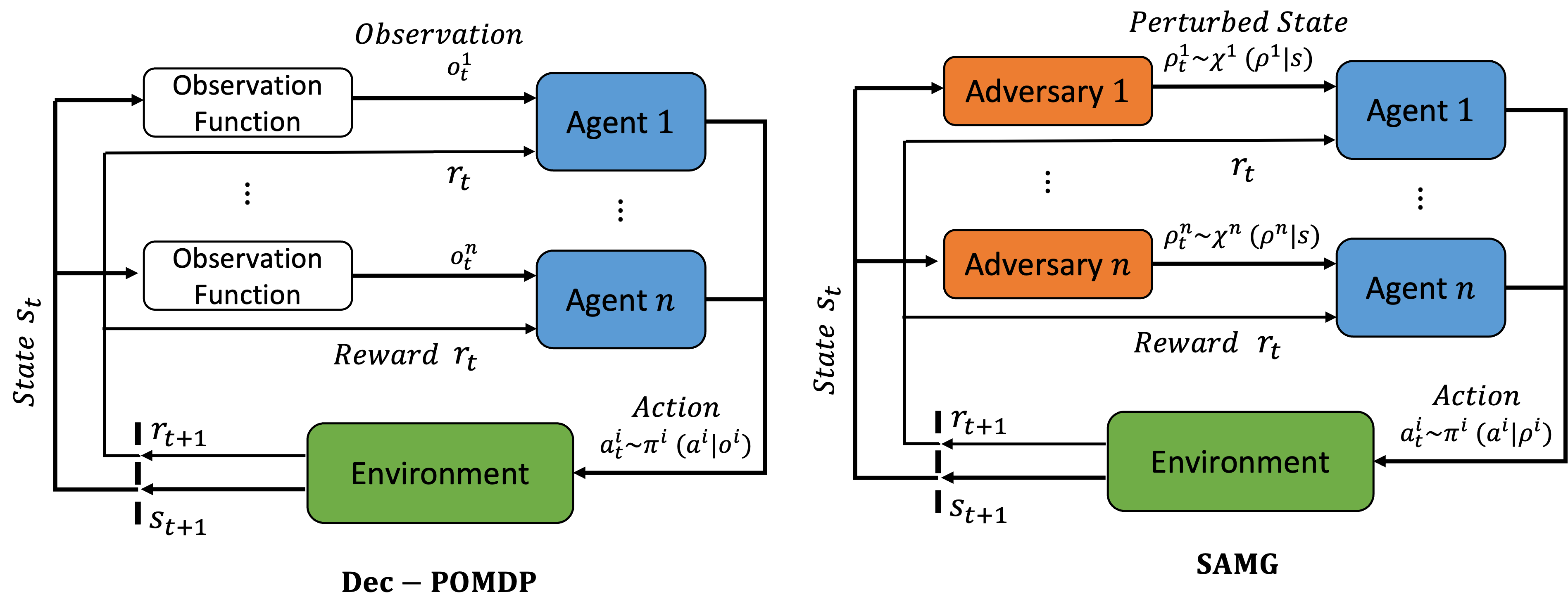
Multi-agent reinforcement learning under adversarial state perturbations. Each agent is associated with an adversary to perturb its knowledge or observation of the true state. Agents want to find a policy \(\pi \) to maximize their total expected return while adversaries want to find a policy \( \chi \) to minimize agents' total expected return.
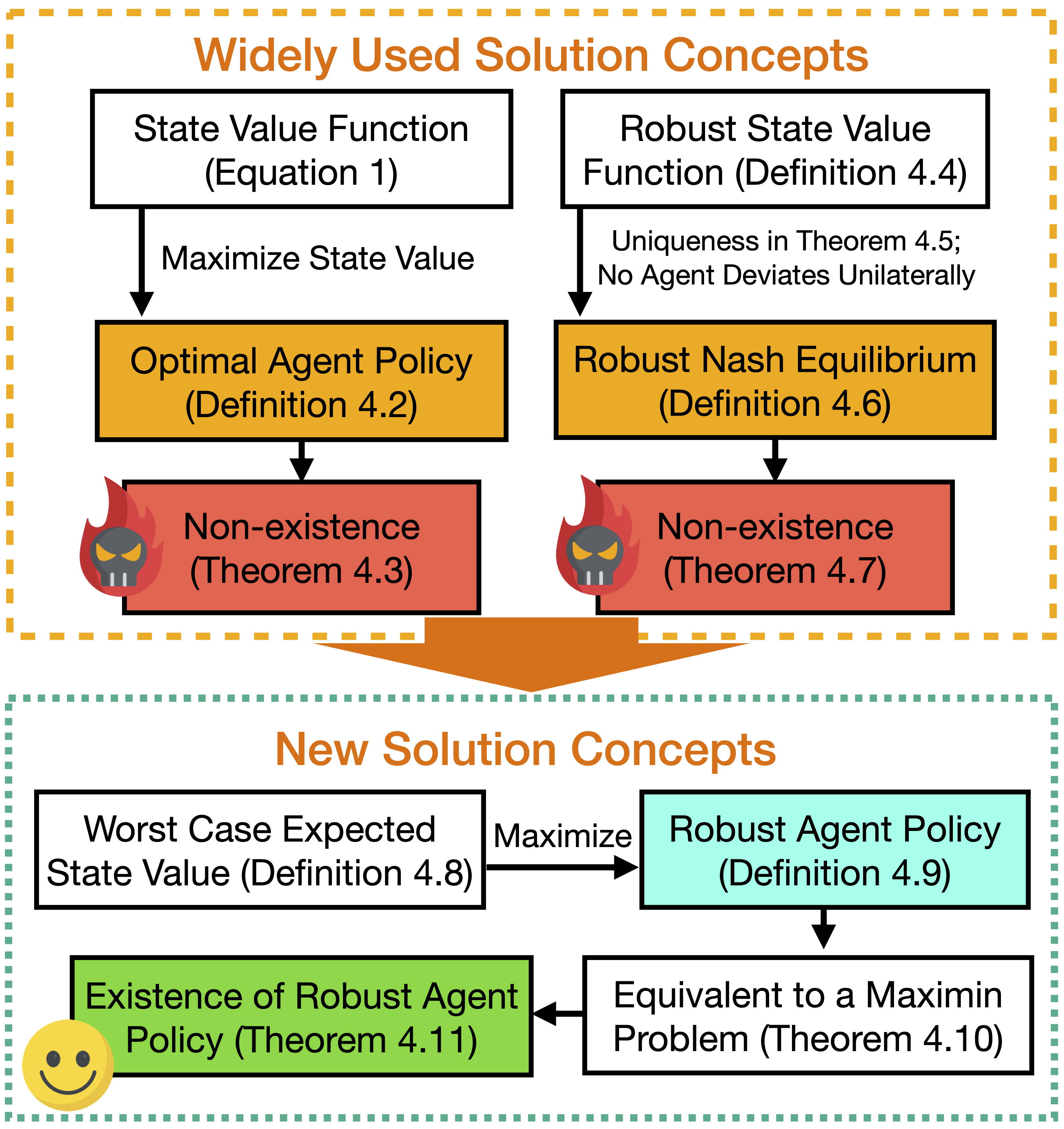
Solution concepts for the SAMGs. We first examine the widely used concepts (optimal agent policy and robust Nash Equilibrium) and demonstrate their non-existence under adversarial state perturbations. In response, we consider a new objective, the worst-case expected state value, and a new solution concept, the robust agent policy.
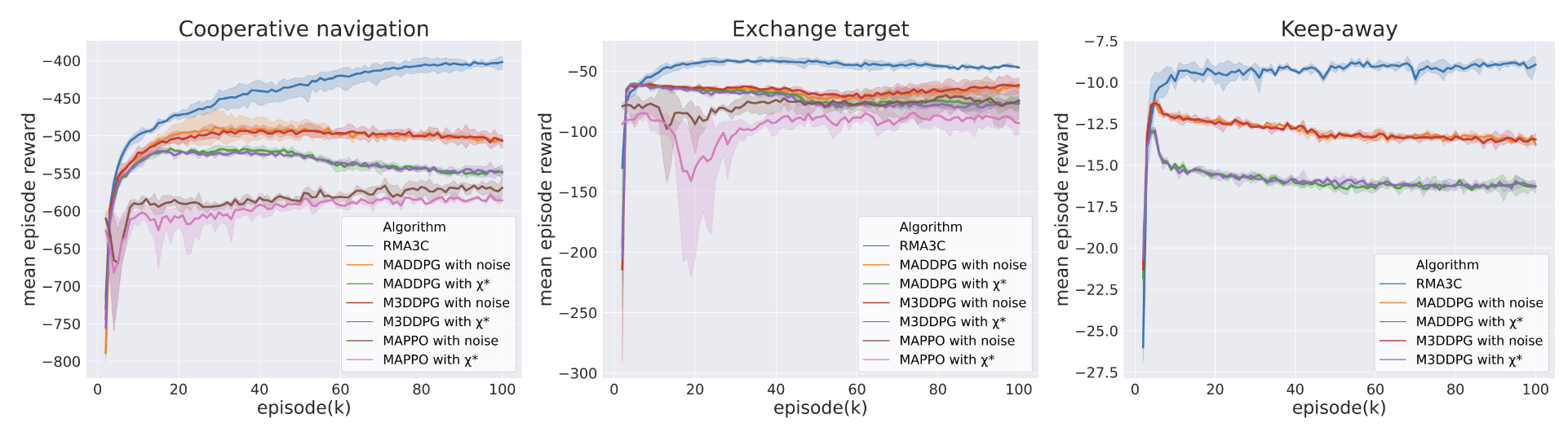
Our RMA3C algorithm compared with several baseline algorithms during the training process. The results showed that our RMA3C algorithm outperforms the baselines, achieving higher mean episode rewards and displaying greater robustness to state perturbations. The baselines were trained under either random state perturbations or a well-trained adversary policy \(\chi^* \). It's worth noting that the MAPPO algorithm only works in fully cooperative tasks, and as such, its results are only reported in the cooperative navigation and exchange target scenarios. Overall, our RMA3C algorithm achieved up to 58.46% higher mean episode rewards than the baselines.
@article{han2022what,
author = {Han, Songyang and Su, Sanbao and He, Sihong and Han, Shuo and Yang, Haizhao and Miao, Fei},
title = {What is the Solution for State-Adversarial Multi-Agent Reinforcement Learning?},
archivePrefix={Transactions on Machine Learning Research (TMLR)},
year = {2024},
}