The recent advancements in wireless technology enable connected autonomous vehicles (CAVs) to gather information about their environment by vehicle-to-vehicle (V2V) communication. In this work, we design an information-sharing-based multi-agent reinforcement learning (MARL) framework for CAVs, to take advantage of the extra information when making decisions to improve traffic efficiency and safety. The safe actor-critic algorithm we propose has two new techniques: the truncated Q-function and safe action mapping. The truncated Q-function utilizes the shared information from neighboring CAVs such that the joint state and action spaces of the Q-function do not grow in our algorithm for a large-scale CAV system. We prove the bound of the approximation error between the truncated-Q and global Q-functions. The safe action mapping provides a provable safety guarantee for both the training and execution based on control barrier functions. Using the CARLA simulator for experiments, we show that our approach can improve the CAV system's efficiency in terms of average velocity and comfort under different CAV ratios and different traffic densities. We also show that our approach avoids the execution of unsafe actions and always maintains a safe distance from other vehicles. We construct an obstacle-at-corner scenario to show that the shared vision can help CAVs to observe obstacles earlier and take action to avoid traffic jams.
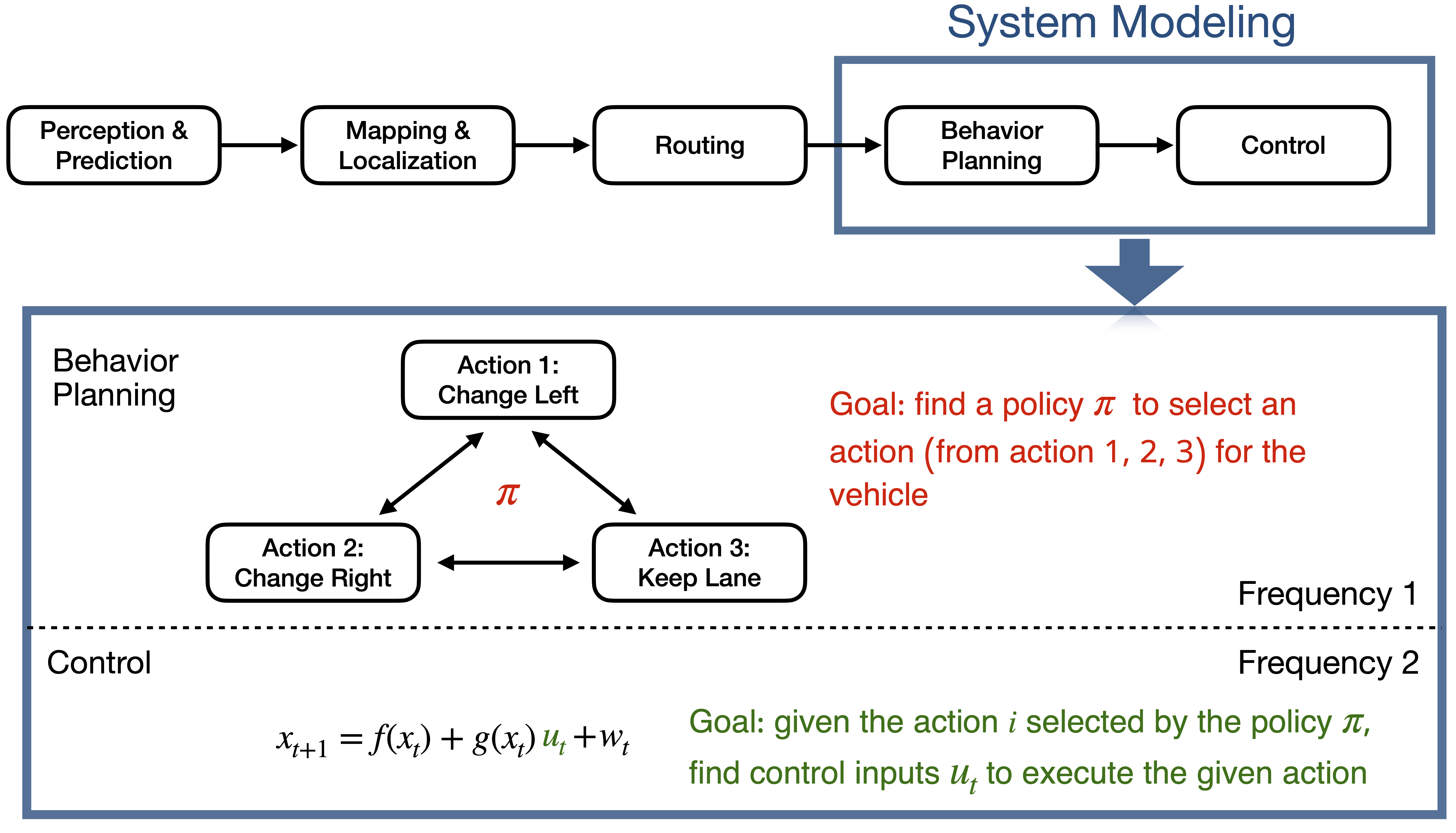
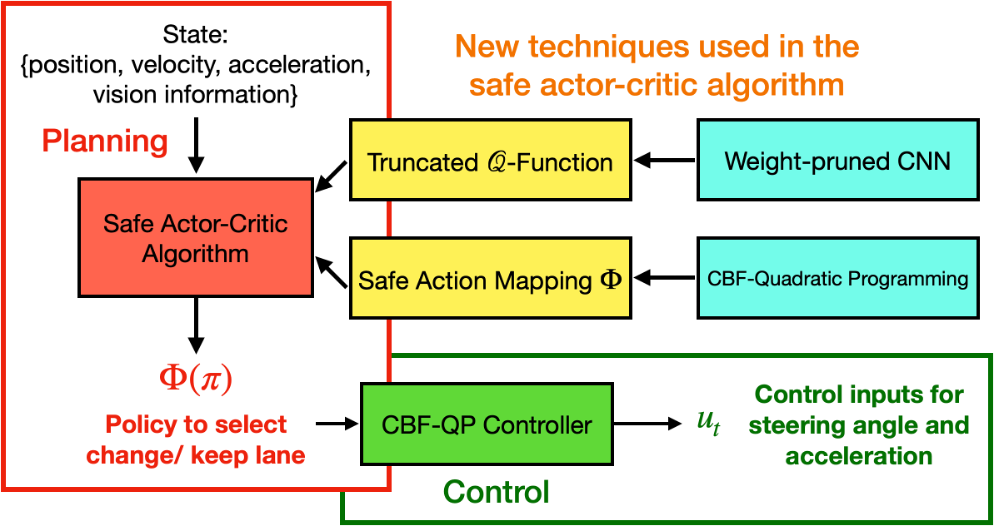
We design a novel safe behavior planning and control framework with decentralized training and decentralized execution to tackle the new challenges for CAVs. One typical workflow for an autonomous vehicle includes perception, prediction, mapping and localization, routing, behavior planning, and control. We focus on the last two modules: the behavior planning module to determine whether to change or keep lanes; the control module to control the steering angle and the acceleration.
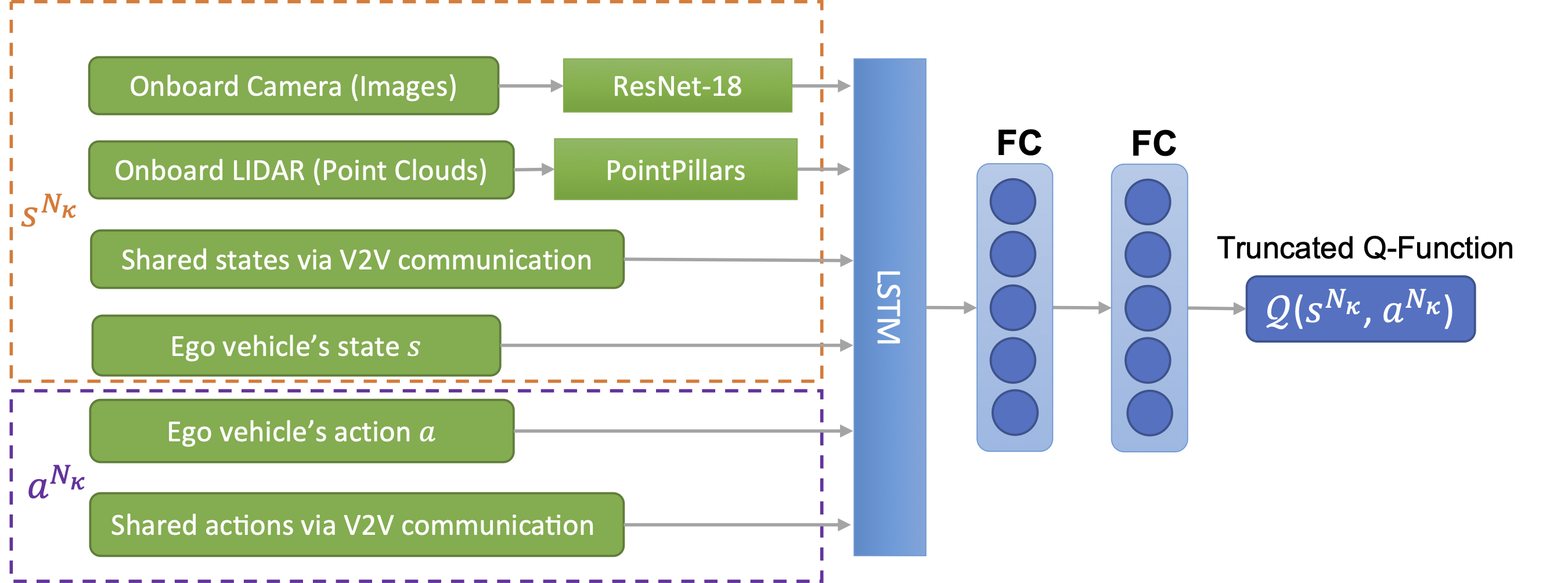
The truncated Q-network for the behavior planning with the LSTM (long short-term memory) layer and FC (fully connected) layers. We use truncated Q-function to approximate the centralized critic such that the training process utilizes the information sharing capability of CAVs instead of relying on the global states and actions.
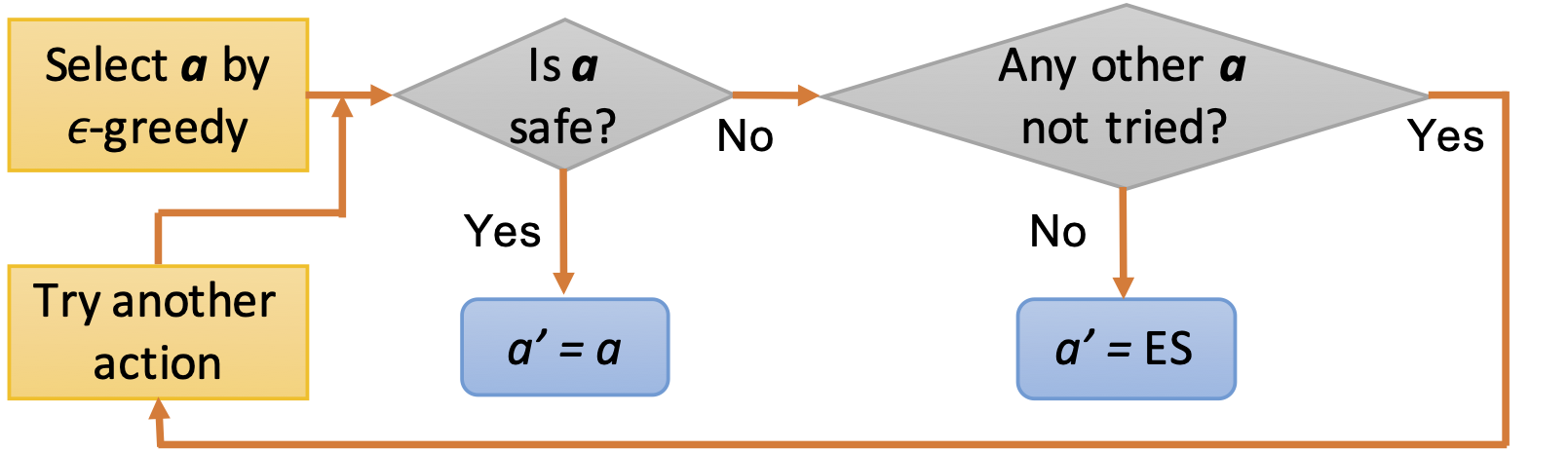
We use safe action mapping to guarantee the action explored in training and implemented in execution is safe with feasible control inputs. We use a control barrier function based quadratic programming (CBF-QP) to evaluate whether an action is safe or not. If the action is safe, then return it; if not, we will search other actions in descending order according to their action value and find a safe one. If all the actions are not safe in the worst case, then we will apply the emergency stop (ES) process.
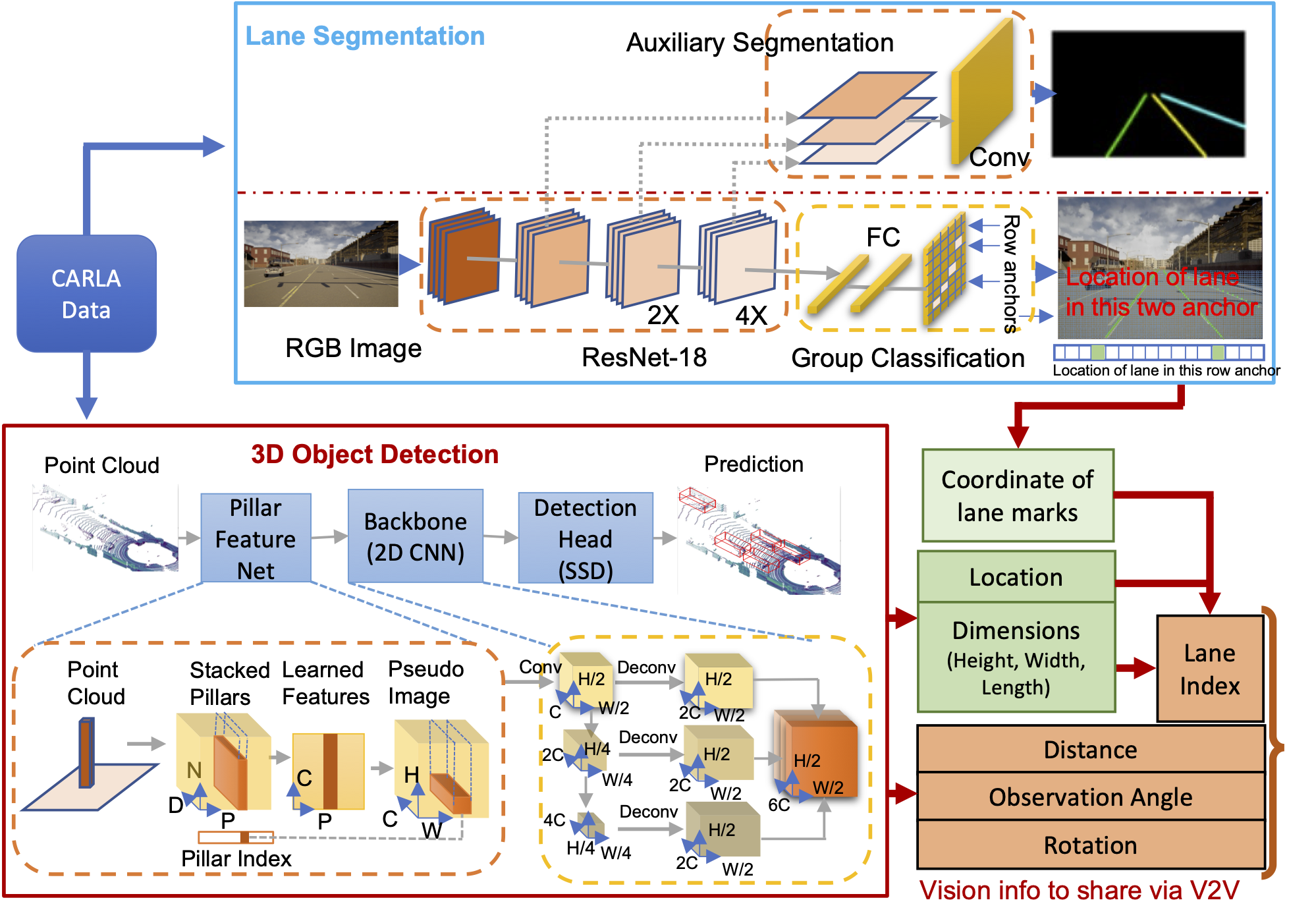
Detailed structure of vision information processing. We combine the lane segmentation and 3D object detection results to extract neighboring vehicles' features. The processed information is included in the state of each CAV.
The obstacle-at-corner scenario where there are obstacles in a left-turning corner. The vehicles on the road are autonomous vehicles. The coming vehicles' view is blocked such that they cannot observe the obstacles. Without any information sharing, there is a traffic jam in the left lane. With shared vision from A or B, using our safe MARL policy, vehicle C can change its lane before it enters the left-turning corner.
@article{han2022behavior,
author = {Han, Songyang and Zhou, Shanglin and Wang, Jiangwei and Pepin, Lynn and Ding, Caiwen and Fu, Jie and Miao, Fei},
title = {A Multi-Agent Reinforcement Learning Approach For Safe and Efficient Behavior Planning Of Connected Autonomous Vehicles},
year={2023},
archivePrefix={IEEE Transactions on Intelligent Transportation Systems}
}